サポートベクトルマシン
Contents
サポートベクトルマシン¶
サポートベクトルマシン全般については次を確認してください。 https://scikit-learn.org/stable/modules/svm.html
データとモジュールのロード
import pandas as pd
from sklearn import model_selection
data = pd.read_csv("input/pn_same_judge_preprocessed.csv")
train, test = model_selection.train_test_split(data, test_size=0.1, random_state=0)
from sklearn.pipeline import Pipeline
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics import ConfusionMatrixDisplay
from sklearn.metrics import PrecisionRecallDisplay
SVC¶
sklearn.svm.LinearSVC を使います。
from sklearn.svm import LinearSVC
pipe = Pipeline([
("vect", TfidfVectorizer(tokenizer=str.split)),
("clf", LinearSVC())
])
pipe.fit(train["tokens"], train["label_num"])
Pipeline(steps=[('vect',
TfidfVectorizer(tokenizer=<method 'split' of 'str' objects>)),
('clf', LinearSVC())])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('vect',
TfidfVectorizer(tokenizer=<method 'split' of 'str' objects>)),
('clf', LinearSVC())])TfidfVectorizer(tokenizer=<method 'split' of 'str' objects>)
LinearSVC()
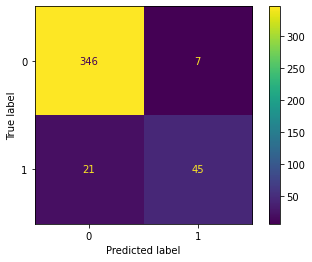
pred = pipe.predict(test["tokens"])
ConfusionMatrixDisplay.from_predictions(y_true=test["label_num"], y_pred=pred)
<sklearn.metrics._plot.confusion_matrix.ConfusionMatrixDisplay at 0x7f1c61f412b0>
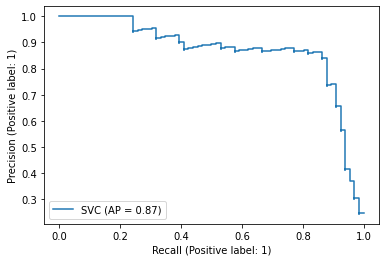
# SVC では predict_proba ではなく decision_function を使います
score = pipe.decision_function(test["tokens"])
PrecisionRecallDisplay.from_predictions(
y_true=test["label_num"],
y_pred=score,
name="SVC",
)
<sklearn.metrics._plot.precision_recall_curve.PrecisionRecallDisplay at 0x7f1c5e01e7f0>
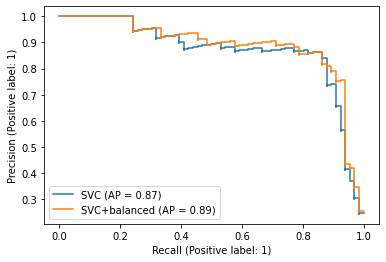
不均衡データに対応する¶
class_weight パラメータで不均衡データに対応できます。
pipe_weight = Pipeline([
("vect", TfidfVectorizer(tokenizer=str.split)),
("clf", LinearSVC(class_weight="balanced"))
])
pipe_weight.fit(train["tokens"], train["label_num"])
Pipeline(steps=[('vect',
TfidfVectorizer(tokenizer=<method 'split' of 'str' objects>)),
('clf', LinearSVC(class_weight='balanced'))])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('vect',
TfidfVectorizer(tokenizer=<method 'split' of 'str' objects>)),
('clf', LinearSVC(class_weight='balanced'))])TfidfVectorizer(tokenizer=<method 'split' of 'str' objects>)
LinearSVC(class_weight='balanced')
score_weight = pipe_weight.decision_function(test["tokens"])
class_weightオプションを付けないモデルと比較します。
import matplotlib.pyplot as plt
_, ax = plt.subplots()
for name, pred in [
("SVC", score),
("SVC+balanced", score_weight),
]:
PrecisionRecallDisplay.from_predictions(ax=ax, y_true=test["label_num"], y_pred=pred, name=name)