ナイーブベイズ分類器
Contents
ナイーブベイズ分類器¶
ナイーブベイスについては以下を参照してください。 https://scikit-learn.org/stable/modules/naive_bayes.html
データとモジュールのロード
import pandas as pd
from sklearn import model_selection
data = pd.read_csv("input/pn_same_judge_preprocessed.csv")
train, test = model_selection.train_test_split(data, test_size=0.1, random_state=0)
from sklearn.pipeline import Pipeline
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics import ConfusionMatrixDisplay
from sklearn.metrics import PrecisionRecallDisplay
MultinomialNB¶
sklearn.naive_bayes.MultinomialNB を使います。
from sklearn.naive_bayes import MultinomialNB
pipe_nb = Pipeline([
("vect", TfidfVectorizer(tokenizer=str.split)),
("clf", MultinomialNB())
])
pipe_nb.fit(train["tokens"], train["label_num"])
Pipeline(steps=[('vect',
TfidfVectorizer(tokenizer=<method 'split' of 'str' objects>)),
('clf', MultinomialNB())])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('vect',
TfidfVectorizer(tokenizer=<method 'split' of 'str' objects>)),
('clf', MultinomialNB())])TfidfVectorizer(tokenizer=<method 'split' of 'str' objects>)
MultinomialNB()
pred_nb = pipe_nb.predict(test["tokens"])
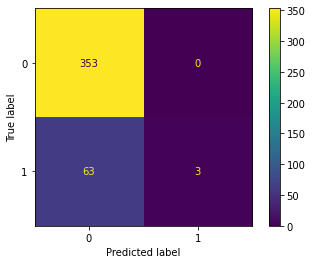
ConfusionMatrixDisplay.from_predictions(y_true=test["label_num"], y_pred=pred_nb)
<sklearn.metrics._plot.confusion_matrix.ConfusionMatrixDisplay at 0x7fc05ee5d490>
score_nb = pipe_nb.predict_proba(test["tokens"])[:,1]
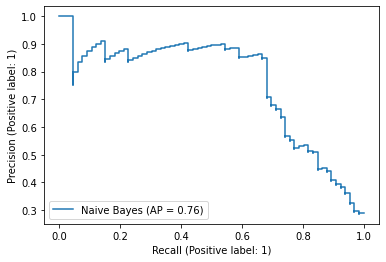
PrecisionRecallDisplay.from_predictions(
y_true=test["label_num"],
y_pred=score_nb,
name="Naive Bayes",
)
<sklearn.metrics._plot.precision_recall_curve.PrecisionRecallDisplay at 0x7fc05af28f10>